
ArXiv
Preprint
Source Code
Github
Model
Weights
Beyond Copying: Are Induction Heads Needed for ICL to Emerge?
Induction heads are attention heads that copy patterns from earlier context, and their emergence during training coincides with a sharp drop in loss, a phenomenon widely cited as evidence that induction heads underlie in-context learning (ICL) more broadly. To test this, we introduce HAPAX, a training regime that omits loss on tokens predictable by induction heads. Despite developing fewer and weaker induction heads without the characteristic loss drop, abstractive ICL capabilities, tasks where answers are not contained in the input, are largely preserved. Our findings suggest that the link between induction heads and the emergence of abstractive ICL is weaker than previously hypothesized.
Induction Circuit

Previous work showed that LLMs develop induction heads that perform inductive copying by matching patterns and copying them from earlier context. Induction circuits consist of three steps:
- Previous token heads allow each token to store which token came before it
- Induction heads attend to the previous token information in earlier contexts, resulting in a "prefix-matching" attention pattern
- The induction head increases the probability of the attended token in the output
Formally, given input tokens (x1, ..., xj), induction circuits operate by searching for tokens that hold information of the current token xj (i.e., searching xi+1 where xi = xj, i < j). If there is a matching xi+1, the induction head increases the logit of xi+1 for the next prediction.
Olsson et al. (2022) hypothesized that these circuits underlie a wide range of in-context learning capabilities. However, subsequent work has demonstrated that induction heads operate in parallel with different components that are more causally important for performance on various ICL tasks. Yin et al. (2025) provide correlational evidence that induction heads transform into other ICL-related heads during training, but it is not clear whether abstractive ICL capabilities can emerge independently from induction heads. This motivates our central question: are induction heads a necessary building block for learning abstractive ICL capabilities, or can such capabilities emerge independently?
HAPAX Training Regime
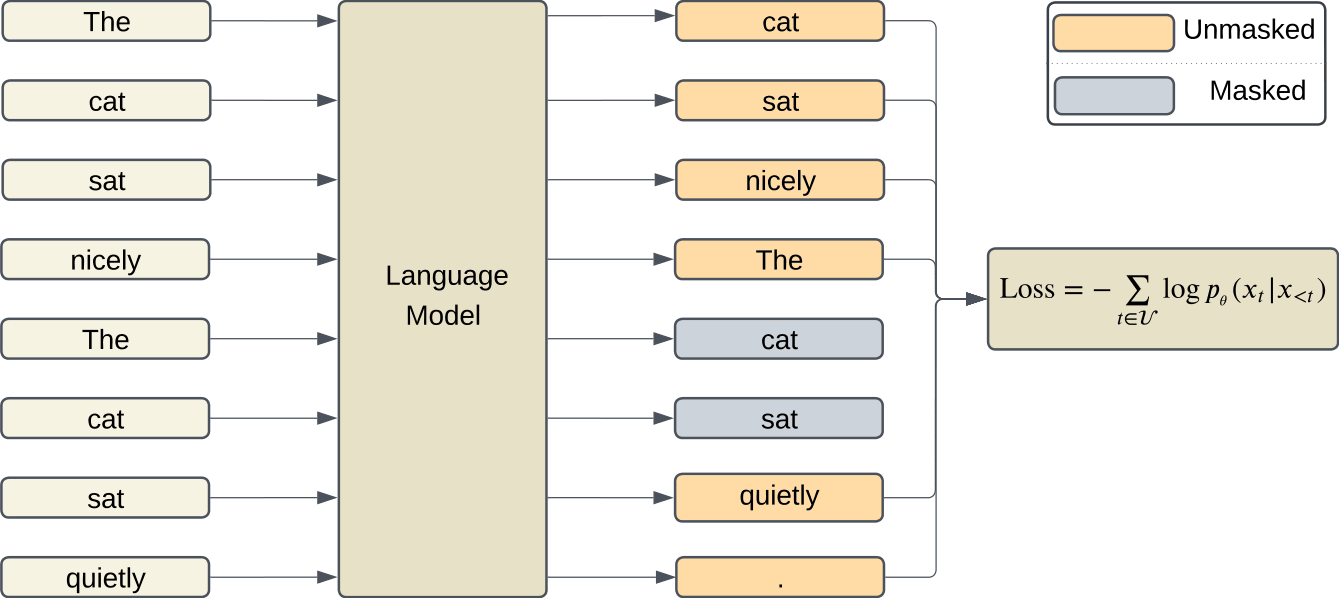
To suppress inductive copying, we apply loss masking to create a training regime where tokens that can be correctly predicted by induction heads are excluded from the loss calculation. Specifically, we mask the loss contributions of token positions that contain a matching n-gram within the same context window (where n > 1). Single-token repetitions are not masked because they cannot be predicted by induction. Thus, the first token of any repeated n-gram is left unmasked.
We train Vanilla and HAPAX 1B models from scratch using the GPT-NeoX architecture with the same hyperparameter and training configuration as the Pythia models. We use the Pile dataset for training. The training data consists of 40B tokens, of which 12.7B (31.7%) tokens are masked for the HAPAX model due to loss masking. This means the HAPAX model never receives gradient signals from repeated n-grams. Since tokens with high representational similarity (e.g., "National" and "_National") can still provide a copying signal, we also train a stricter variant, Thresholded-HAPAX, that additionally masks such tokens (52.5% of tokens masked).
Suppression of Inductive Copying
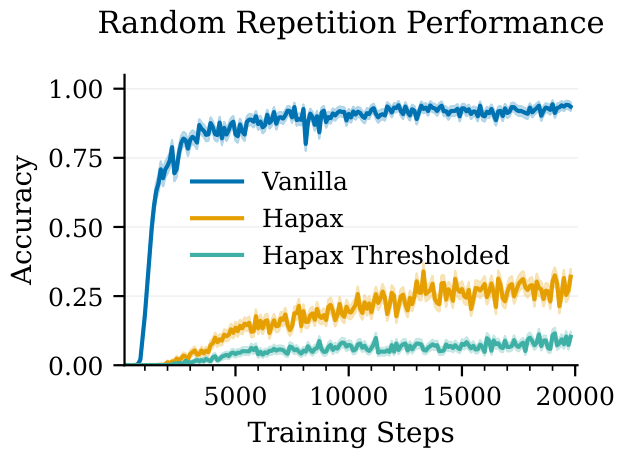
We first measure random repetition performance: the model is given 1000 sequences of random repeated tokens r1r2...rsr1r2...rs-1 and is expected to predict rs. This synthetic task does not occur in natural language but is solvable through induction heads. The HAPAX model experiences a 66% drop and Thresholded-HAPAX experiences an 89% drop in accuracy relative to the vanilla model at the end of training.
We evaluate HAPAX on 28 extractive tasks from Todd et al. (2024). Of the 24 tasks with statistically significant differences, 23 show reduced performance. The results confirm that the HAPAX training regime effectively reduces inductive copying.
Preservation of Abstractive ICL Capabilities
| Task | Van. | HAP. | Thr. | Task | Van. | HAP. | Thr. |
|---|---|---|---|---|---|---|---|
| AG News | 34.5 | 7.4 | 1.4 | Antonym | 1.0 | 2.2 | 7.6 |
| Cap. Second Letter | 12.1 | 2.7 | 3.7 | CommonsenseQA | 18.4 | 9.4 | 6.9 |
| Country-Capital | 29.6 | 42.3 | 29.6 | Cap. (Full Word) | 79.1 | 62.2 | 52.2 |
| Cap. First Letter | 38.5 | 68.6 | 28.7 | Cap. Last Letter | 9.7 | 3.4 | 3.9 |
| Country-Currency | 6.5 | 5.4 | 2.2 | Lower. First Letter | 71.4 | 69.4 | 58.1 |
| National Parks | 16.4 | 21.7 | 17.1 | Next Cap. Letter | 6.4 | 6.0 | 4.7 |
| Landmark-Country | 32.8 | 36.5 | 22.0 | Lower. Last Letter | 6.9 | 7.2 | 3.3 |
| Next Item | 10.7 | 27.6 | 9.8 | Park-Country | 12.2 | 16.9 | 15.3 |
| Present-Past | 54.6 | 78.8 | 41.6 | Previous Item | 5.3 | 8.0 | 2.2 |
| Product-Company | 20.5 | 20.7 | 9.0 | Sentiment | 64.1 | 15.8 | 0.0 |
| Singular-Plural | 62.0 | 77.1 | 34.6 | Synonym | 2.1 | 2.2 | 3.8 |
| Word Length | 8.1 | 6.9 | 1.2 | Person-Instrument | 23.7 | 1.4 | 1.4 |
| Person-Occupation | 18.3 | 4.6 | 6.2 | Person-Sport | 22.0 | 27.4 | 0.0 |
| Task | Van. | HAP. | Thr. | Task | Van. | HAP. | Thr. |
|---|---|---|---|---|---|---|---|
| AG News | 0.3 | 7.8 | 3.7 | Antonym | 0.8 | 2.5 | 7.0 |
| Cap. Second Letter | 0.5 | 3.2 | 7.6 | CommonsenseQA | 12.0 | 13.9 | 7.3 |
| Country-Capital | 30.7 | 42.3 | 29.6 | Cap. (Full Word) | 79.1 | 62.2 | 52.2 |
| Cap. First Letter | 36.4 | 73.6 | 31.2 | Cap. Last Letter | 2.9 | 6.6 | 8.2 |
| Country-Currency | 4.3 | 4.3 | 3.2 | Lower. First Letter | 73.3 | 76.2 | 69.2 |
| National Parks | 15.3 | 22.6 | 25.3 | Next Cap. Letter | 3.4 | 8.6 | 6.3 |
| Landmark-Country | 30.4 | 38.4 | 26.1 | Lower. Last Letter | 3.8 | 10.0 | 5.2 |
| Next Item | 12.0 | 28.0 | 12.0 | Park-Country | 10.7 | 16.7 | 16.1 |
| Present-Past | 54.6 | 78.8 | 41.6 | Previous Item | 5.3 | 7.1 | 1.8 |
| Product-Company | 15.9 | 24.9 | 20.7 | Sentiment | 2.8 | 35.4 | 0.0 |
| Singular-Plural | 62.0 | 77.1 | 34.6 | Synonym | 1.6 | 2.0 | 3.8 |
| Word Length | 7.7 | 14.9 | 2.0 | Person-Instrument | 0.2 | 3.9 | 1.6 |
| Person-Occupation | 0.2 | 2.6 | 7.8 | Person-Sport | 9.7 | 44.7 | 2.5 |
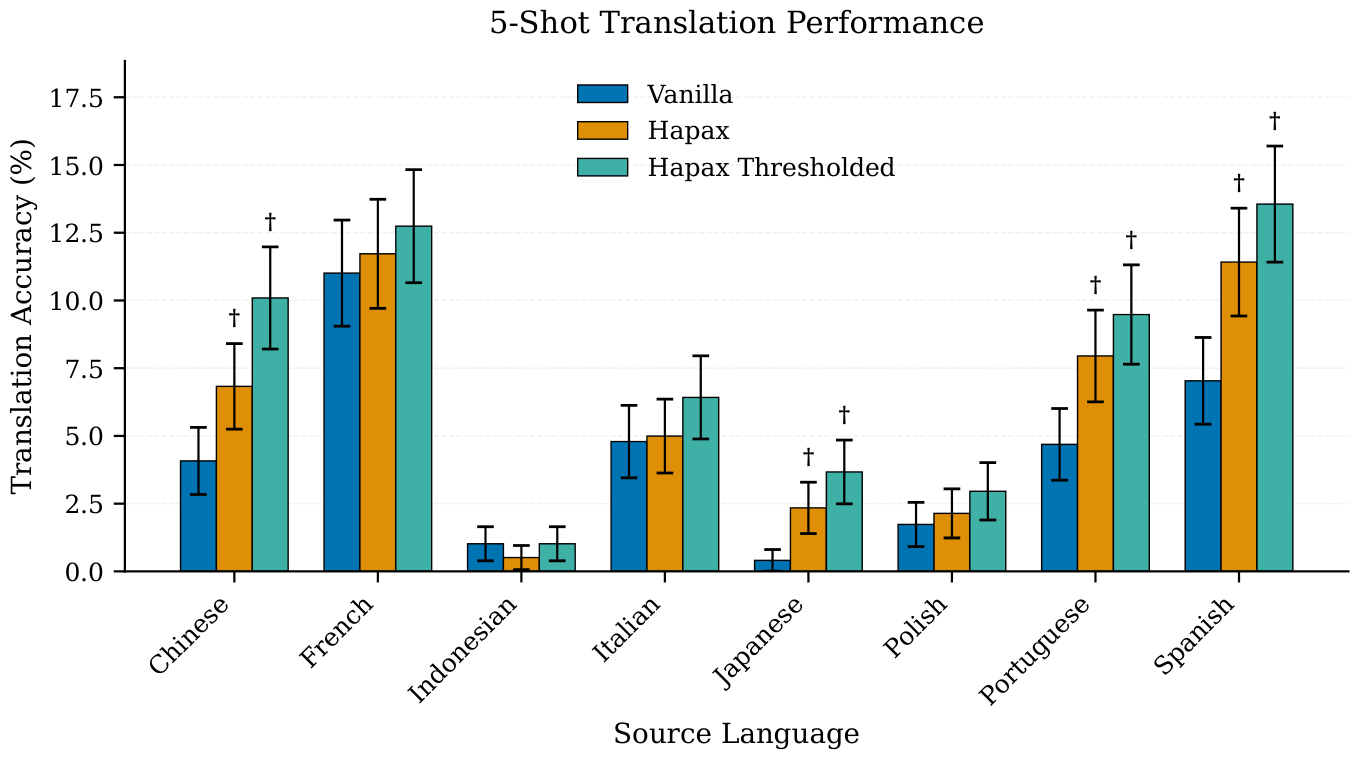
We continue our evaluation with abstractive tasks, where the model needs to generate novel information not contained in the context. We evaluate on 26 abstractive tasks (e.g., Country-Capital task) and 8 word-level translation tasks.
Our evaluations suggest that models trained with HAPAX preserve abstractive ICL capabilities, with HAPAX achieving higher accuracy on 13 out of 21 tasks with statistically significant differences. When we control for label overlap (ensuring target answers don't appear in few-shot examples), the HAPAX model achieves higher accuracy on 24 out of 25 tasks. If abstractive ICL capabilities were fundamentally dependent on induction heads and inductive copying capability, we would expect performance degradation across most tasks when inductive copying is substantially reduced. However, our results do not show such degradation. Despite receiving gradients from far fewer tokens, the HAPAX model preserves its abstractive ICL capabilities.
In-Context Learning Beyond N-gram Copying
We use the token-loss difference metric to understand general ICL capabilities. This metric is defined by the differences of the cross-entropy loss of arbitrary token positions, conventionally using the 500th and 50th token positions. Intuitively, token-loss difference measures improvement across increasing token positions. If the loss at token 500 is lower and TLD > 0, it shows that the model's predictions improved with increasing context.
Yin et al. (2025) provided evidence that the metric is strongly influenced by induction heads but does not correlate well with in-context learning task performance. Our results demonstrate that the sudden increase in token-loss difference metric for the vanilla model is indicative of the emergence of inductive copying capabilities, but lacks indicative power for the emergence of abstractive ICL capabilities.
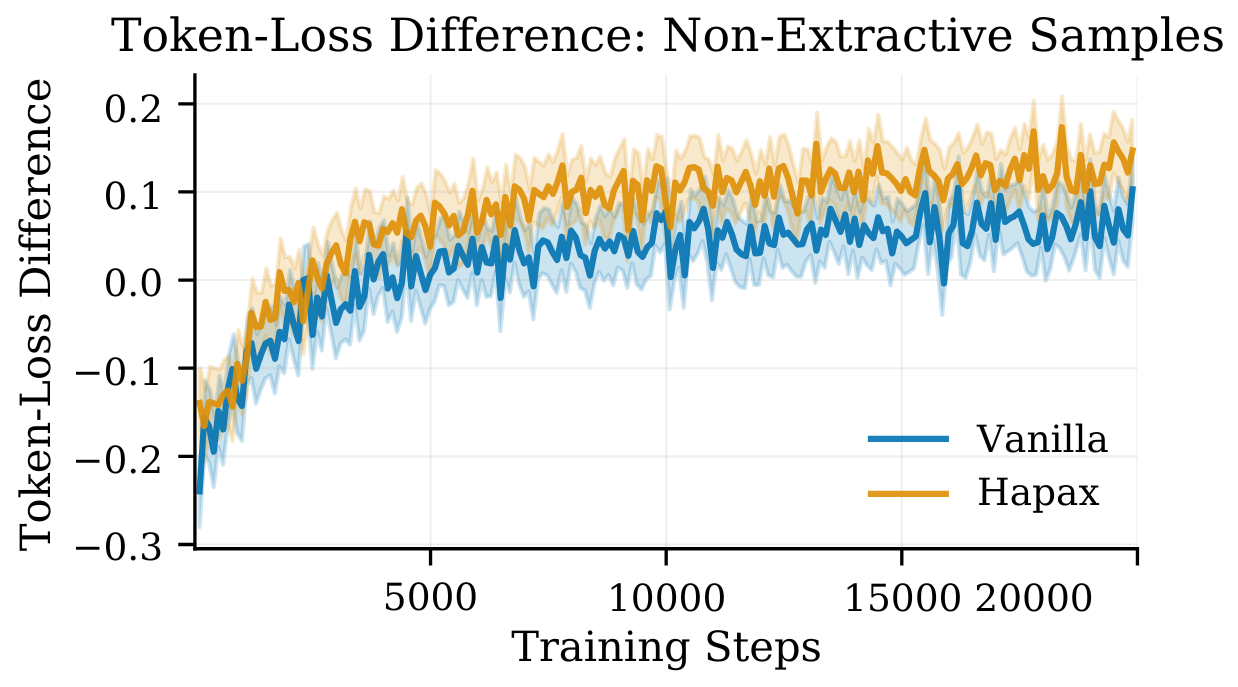
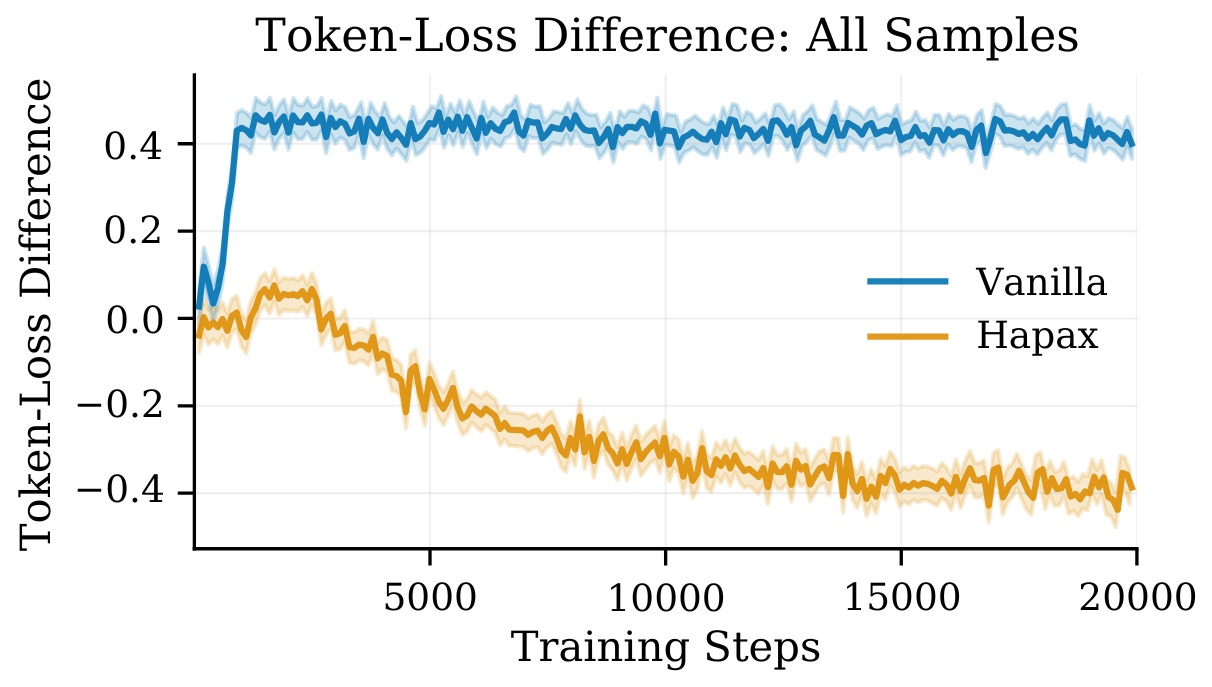
To investigate this hypothesis further, we propose using samples where neither the 500th nor the 50th token can be predicted correctly with inductive copying. With this modification, we observe that, contrary to the regular token-loss difference metric, the HAPAX model has a slightly higher token-loss difference, which suggests that it can leverage context better for non-exact copying instances. We also observe that the model's ability to leverage context for non-exact matching tokens does not exhibit a phase shift but rather improves gradually across training steps.
Mechanistic Analysis of Induction Heads
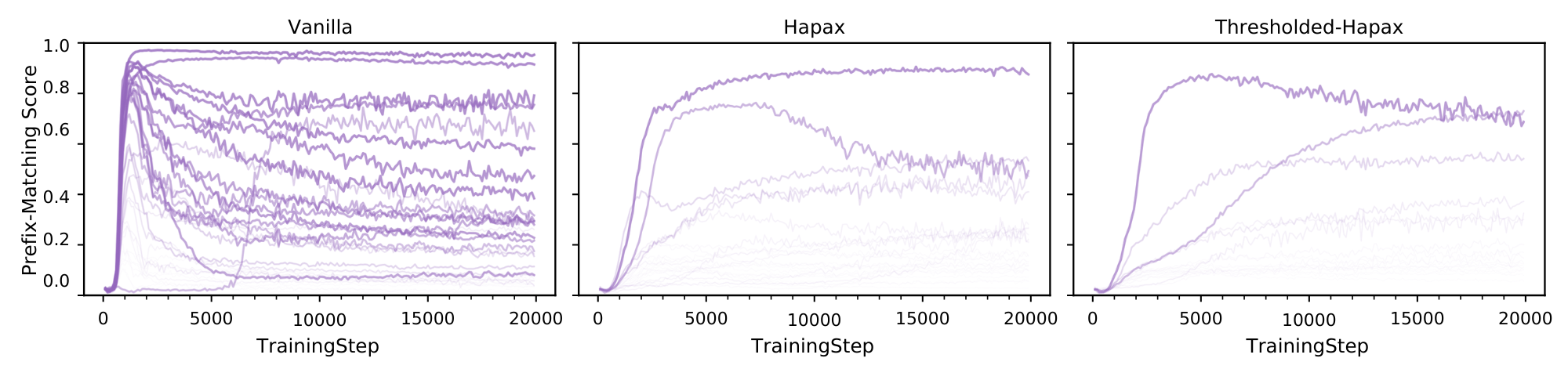
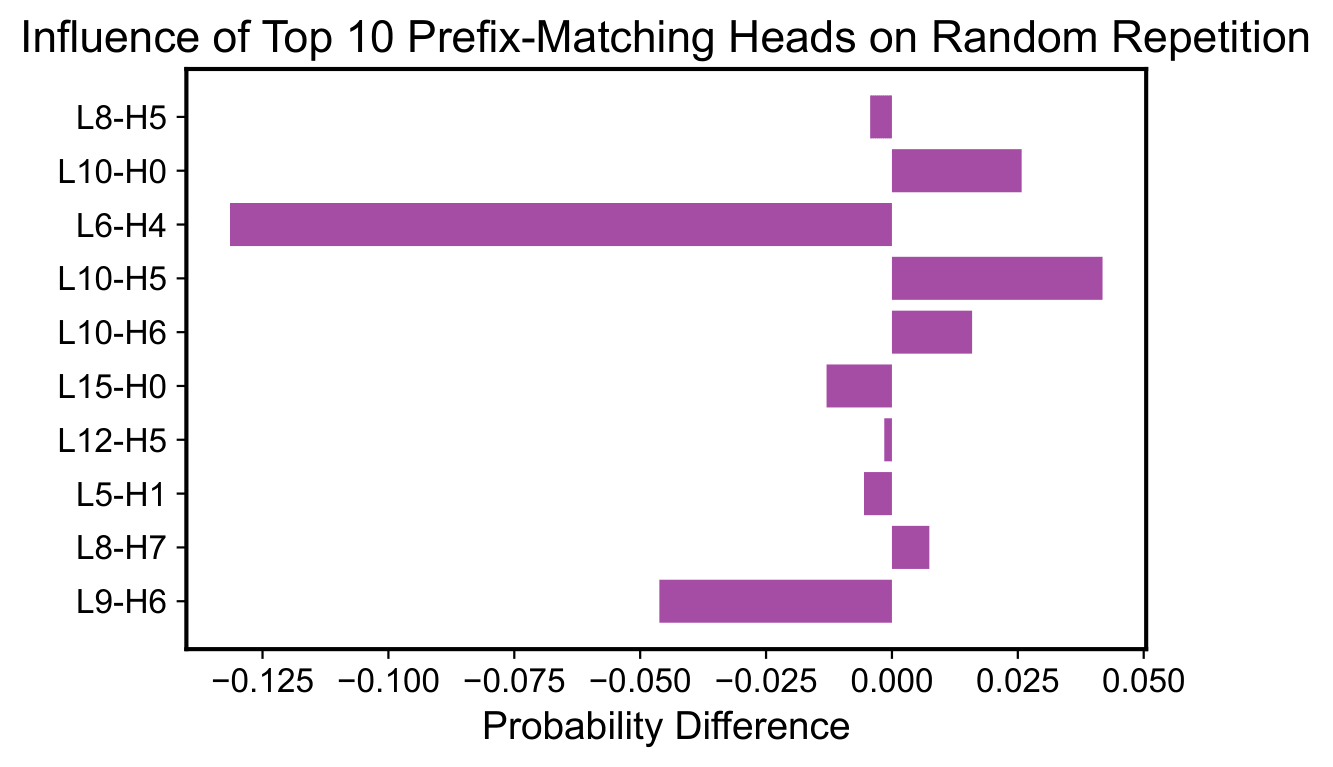
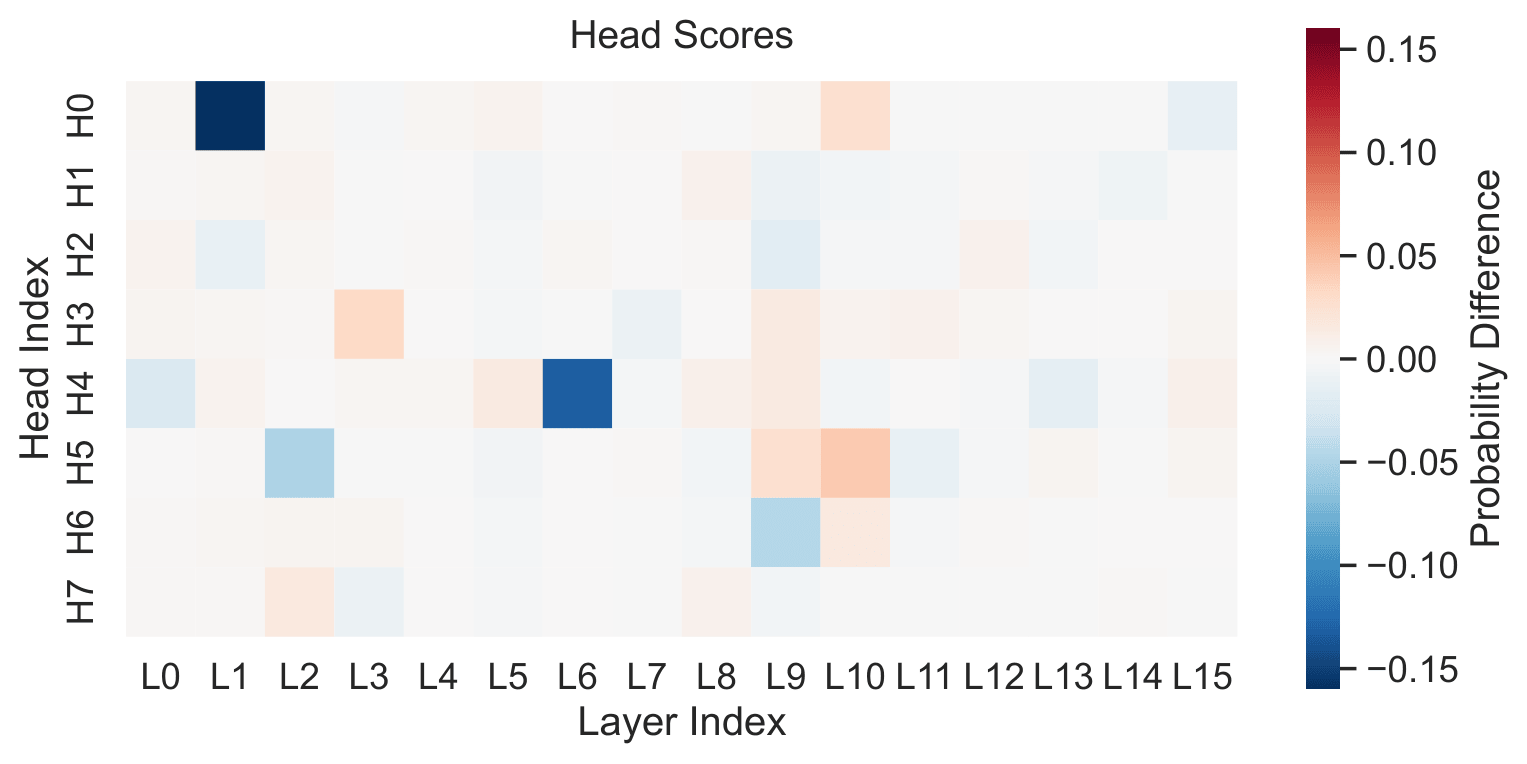
With inductive copying suppressed, we next investigate mechanistically how induction heads are affected. We analyze the attention patterns of attention heads for the vanilla and HAPAX models using the random repetition sequence. HAPAX has fewer attention heads that strongly display the prefix-matching pattern commonly associated with induction heads.
In the vanilla model, the top 10 prefix-matching heads achieve an average score of 61%, whereas in HAPAX this average drops to 40% and 36% for Thresholded-HAPAX. We observe that the vanilla model contains many heads whose prefix-matching scores spike early in training and then decay, while the Hapax variants show fewer rise-then-decay trajectories and fewer heads that ever reach high prefix-matching scores.
Using ablation studies, we analyze the causal impact of each individual attention head. We observe that out of the top 10 prefix matching heads, 6 of the heads negatively influence the probability assigned to the correct token, meaning that they functionally behave closer to an anti-induction head. Despite many of the top 10 prefix-matching heads negatively influencing prediction, abstractive ICL capabilities remain intact. This suggests that learning abstractive ICL is robust against the suppression of inductive copying.
Origins of Prefix-Matching Patterns
With HAPAX training, we obtained a model that does not benefit from repetition. However, our data distribution plausibly does not imply anything about the existence of previous token heads, and they might still be helpful for tasks such as detokenization. In this section, we conduct experiments to ascertain the influence of previous token heads on the formation of induction heads.
If models must develop previous token heads for reasons other than learning induction circuits, heads in later layers may naturally develop prefix-matching attention patterns as they attend to this information. We find that even randomly initialized heads at later layers will attend to previous token information, suggesting that prefix-matching patterns can form as a direct result of the presence of previous token information.
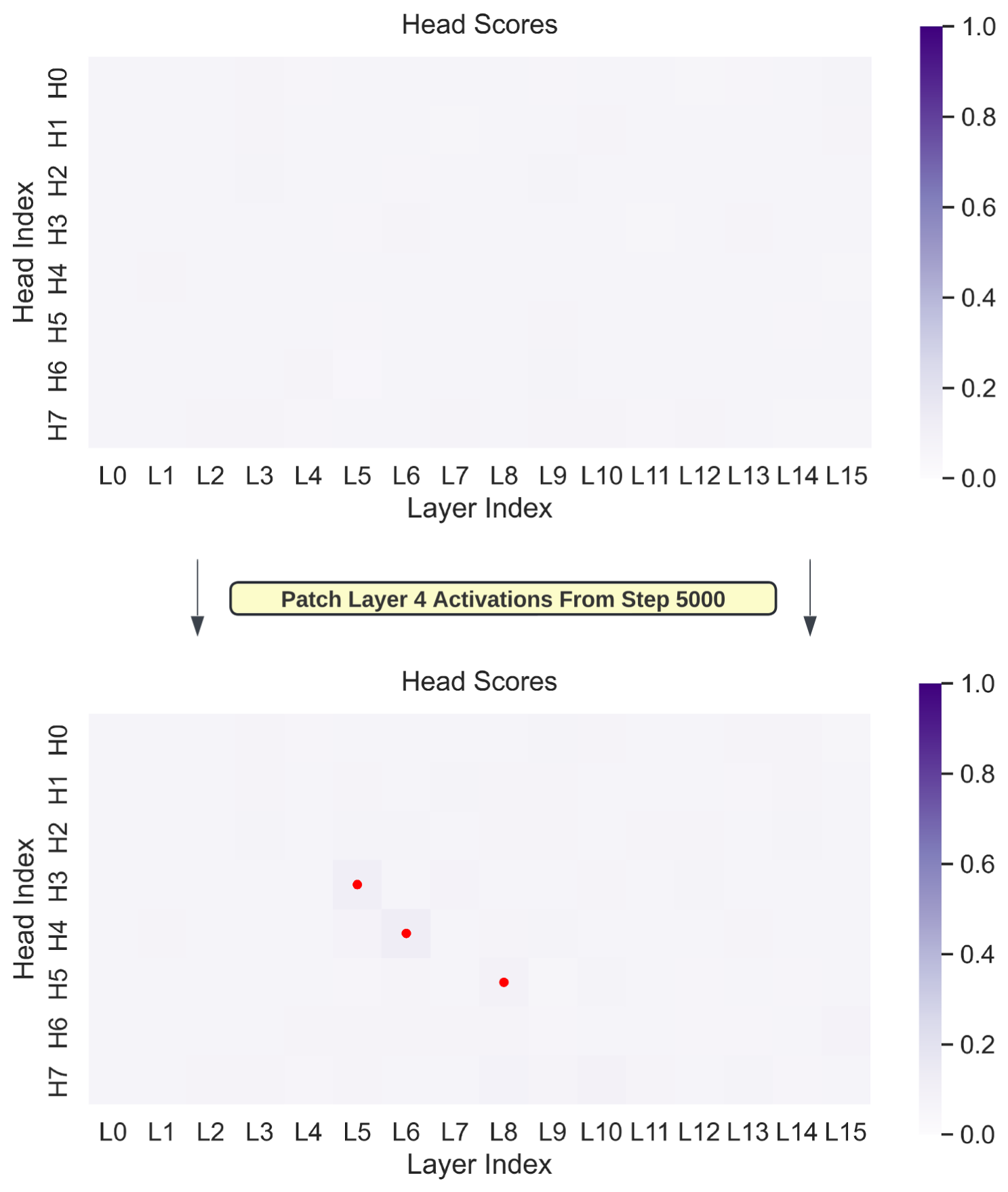
These results suggest that induction head-like attention patterns can form quite easily once previous token information is present, possibly explaining how the HAPAX model still displays such attention patterns despite never being trained on token positions that can be predicted by induction heads.
Key Takeaways
Our findings suggest that abstractive ICL capabilities follow more independent developmental pathways from induction heads than previously hypothesized. While prior work proposed that induction heads underlie a wide range of ICL capabilities, HAPAX models preserve abstractive ICL despite significantly reduced inductive copying and weaker induction heads. This provides new insight into the training dynamics of transformers: the mechanisms underlying different ICL capabilities are less tightly coupled than the correlated emergence of these abilities would suggest.
Related Work
Our work builds on research investigating induction heads, in-context learning mechanisms, training dynamics, and the role of repetition in language models.
Attention Heads and In-Context Learning
 Nelson Elhage, Neel Nanda, Catherine Olsson, et al. A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread, 2021.
Nelson Elhage, Neel Nanda, Catherine Olsson, et al. A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread, 2021.
Notes: The authors introduce a mathematical framework for understanding transformer circuits and identify induction circuits responsible for inductive copying, where LLMs match patterns and copy them from earlier context.
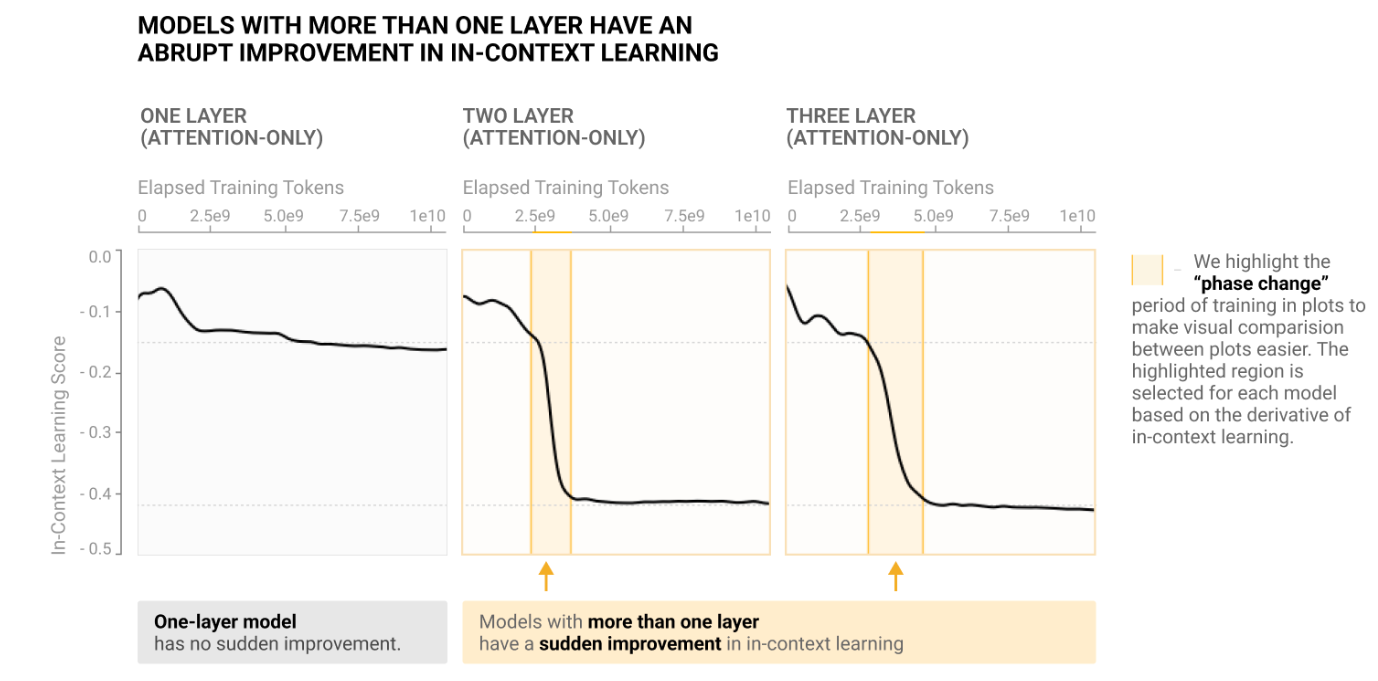 Catherine Olsson, Nelson Elhage, Neel Nanda, et al. In-context Learning and Induction Heads. Transformer Circuits Thread, 2022.
Catherine Olsson, Nelson Elhage, Neel Nanda, et al. In-context Learning and Induction Heads. Transformer Circuits Thread, 2022.
Notes: The first mechanistic analysis of ICL capabilities in LLMs. The authors find that the development of induction circuits is associated with rapid phase transitions as the model displays prefix-matching and inductive copying capabilities, with a general increase in ICL capabilities following later in training. They hypothesize that induction heads underlie a wide range of ICL capabilities and observe that some heads are also involved in "fuzzy" copying based on semantic similarity.
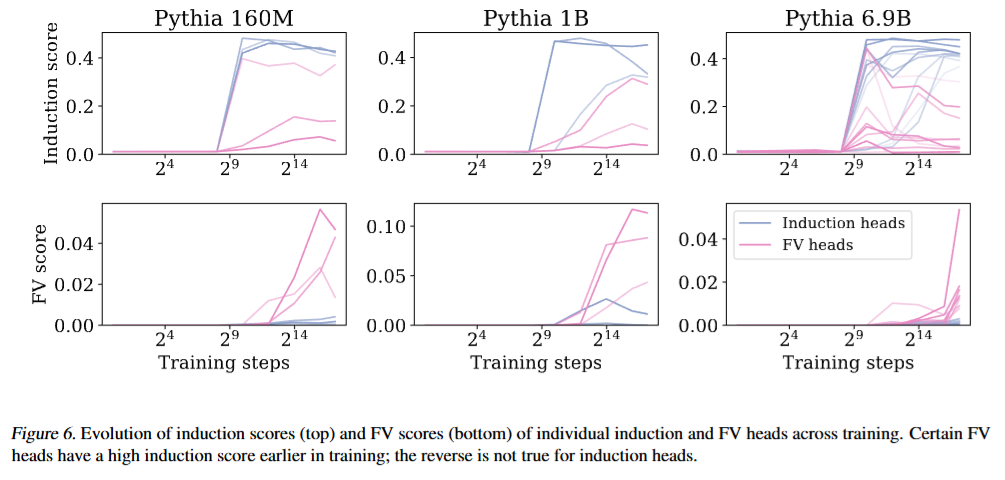 Kayo Yin, Jacob Steinhardt. Which Attention Heads Matter for In-Context Learning? ICML, 2025.
Kayo Yin, Jacob Steinhardt. Which Attention Heads Matter for In-Context Learning? ICML, 2025.
Notes: The authors show that ablation of traditional induction heads does not damage ICL as much as ablation of function vector heads. They also observe that certain heads displaying high prefix-matching scores early in training later transform into function vector heads, suggesting a potential developmental link between induction heads and other ICL-related heads.
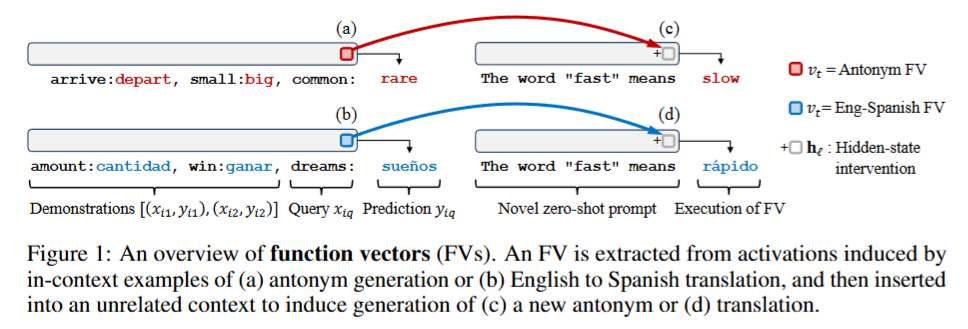 Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, David Bau. Function Vectors in Large Language Models. ICLR, 2024.
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, David Bau. Function Vectors in Large Language Models. ICLR, 2024.
Notes: The authors identify function vector heads that trigger ICL tasks and introduce extractive tasks (where the model must directly extract the answer from the input) and abstractive tasks (which require generating new answers rather than copying) that are used within our work to analyze different ICL capabilities.
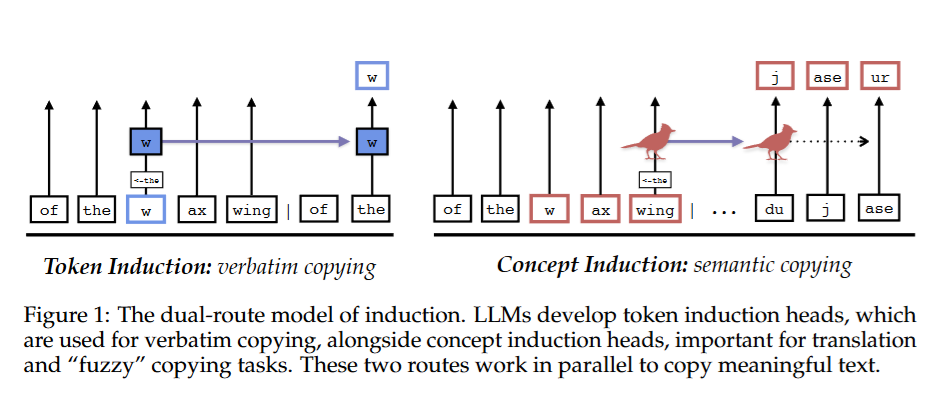 Sheridan Feucht, Eric Todd, Byron C. Wallace, David Bau. The Dual-Route Model of Induction. CoLM, 2025.
Sheridan Feucht, Eric Todd, Byron C. Wallace, David Bau. The Dual-Route Model of Induction. CoLM, 2025.
Notes: The authors show that models contain separate concept induction circuits that are causally more important than traditional induction circuits for "fuzzy" copying tasks (e.g., translation).
Training Dynamics and Induction Heads
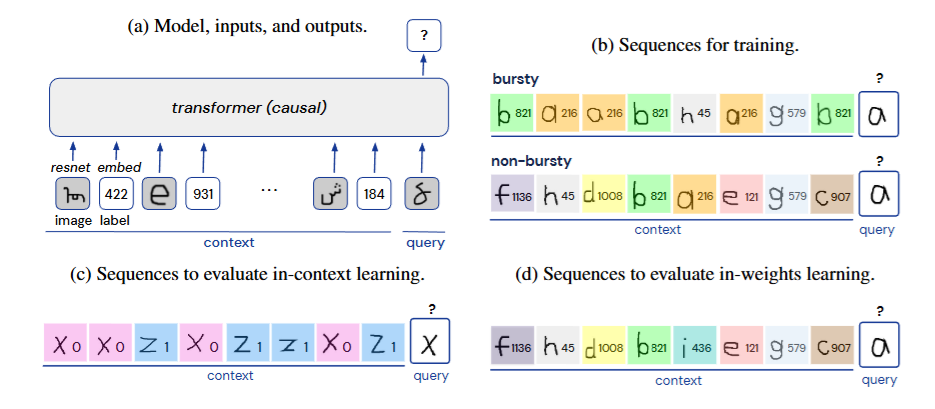 Stephanie C.Y. Chan, Adam Santoro, Andrew K. Lampinen, Jane X. Wang, Aaditya K. Singh, Pierre H. Richemond, James L. McClelland, Felix Hill. Data Distributional Properties Drive Emergent In-Context Learning in Transformers. NeurIPS, 2022.
Stephanie C.Y. Chan, Adam Santoro, Andrew K. Lampinen, Jane X. Wang, Aaditya K. Singh, Pierre H. Richemond, James L. McClelland, Felix Hill. Data Distributional Properties Drive Emergent In-Context Learning in Transformers. NeurIPS, 2022.
Notes: The authors identify data distributional properties that drive the emergence of in-context learning, showing how skewed Zipfian distributions lead to the emergence of ICL. Importantly, they demonstrate that Zipfian distributions enable both in-context and weight-based learning to co-exist, resolving an initial trade-off between the two learning modes.
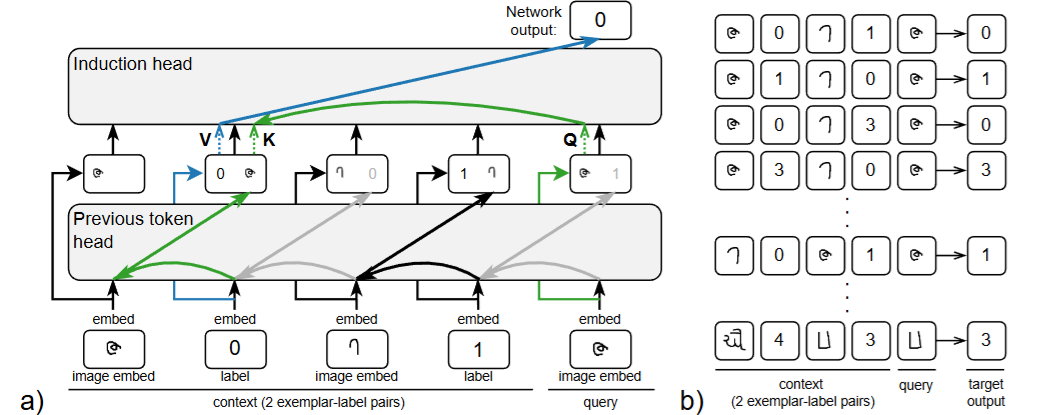 Aaditya K. Singh, Ted Moskovitz, Felix Hill, Stephanie C.Y. Chan, Andrew M. Saxe. What Needs to Go Right for an Induction Head? A Mechanistic Study of In-Context Learning Circuits and Their Formation. ICML, 2024.
Aaditya K. Singh, Ted Moskovitz, Felix Hill, Stephanie C.Y. Chan, Andrew M. Saxe. What Needs to Go Right for an Induction Head? A Mechanistic Study of In-Context Learning Circuits and Their Formation. ICML, 2024.
Notes: The authors use clamping to study subcomponents of induction circuits and their effect on phase changes. Using an optogenetics-inspired causal framework, they identify three underlying subcircuits that interact to drive induction head formation.
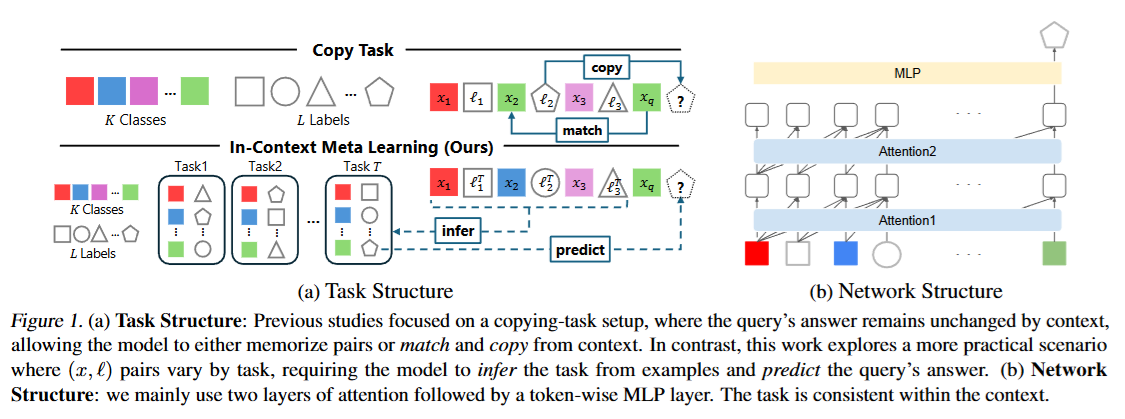 Gouki Minegishi, Hiroki Furuta, Shohei Taniguchi, Yusuke Iwasawa, Yutaka Matsuo. Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence. ICML, 2025.
Gouki Minegishi, Hiroki Furuta, Shohei Taniguchi, Yusuke Iwasawa, Yutaka Matsuo. Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence. ICML, 2025.
Notes: The authors study a meta-learning setting to investigate mechanisms in non-exact copying scenarios. They find that this meta-learning ability emerges in multiple training phases, with a different circuit appearing in each phase rather than a single induction-head transition.
Loss Masking and Repetition
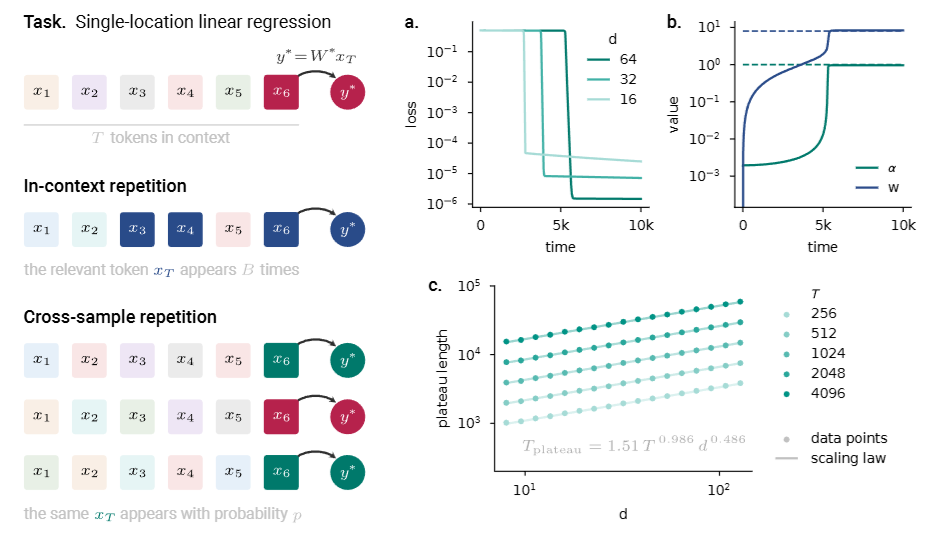 Nicolas Zucchet, Francesco D'Angelo, Andrew Kyle Lampinen, Stephanie C.Y. Chan. The Emergence of Sparse Attention: Impact of Data Distribution and Benefits of Repetition. NeurIPS, 2025.
Nicolas Zucchet, Francesco D'Angelo, Andrew Kyle Lampinen, Stephanie C.Y. Chan. The Emergence of Sparse Attention: Impact of Data Distribution and Benefits of Repetition. NeurIPS, 2025.
Notes: The authors analyze how training data repetition speeds up emergent behavior in language models, showing the importance of repetition in the data distribution for emergent behavior.
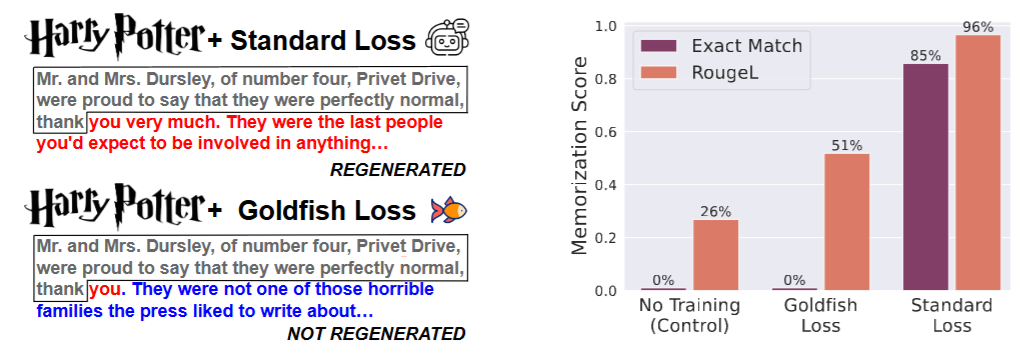 Abhimanyu Hans, John Kirchenbauer, Yuxin Wen, Neel Jain, Hamid Kazemi, Prajwal Singhania, Siddharth Singh, Gowthami Somepalli, Jonas Geiping, Abhinav Bhatele, Tom Goldstein. Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs. NeurIPS, 2024.
Abhimanyu Hans, John Kirchenbauer, Yuxin Wen, Neel Jain, Hamid Kazemi, Prajwal Singhania, Siddharth Singh, Gowthami Somepalli, Jonas Geiping, Abhinav Bhatele, Tom Goldstein. Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs. NeurIPS, 2024.
Notes: The authors incorporate loss masking strategies to prevent memorization of private information, excluding the loss contributions of certain tokens.
 Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, Jason Weston. Neural Text Generation With Unlikelihood Training. ICLR, 2020.
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, Jason Weston. Neural Text Generation With Unlikelihood Training. ICLR, 2020.
Notes: The authors present unlikelihood loss training to mitigate repetitions in the model. They observe that the resulting models give less repetitive, less dull text while maintaining perplexity, giving superior generations.
How to cite
The paper can be cited as follows.
bibliography
Kerem Sahin, Sheridan Feucht, Adam Belfki, Jannik Brinkmann, Aaron Mueller, David Bau, Chris Wendler. "In-Context Learning Without Copying." arXiv preprint arXiv:2511.05743, (2025).
bibtex
@misc{sahin2025incontextlearningcopying,
title={In-Context Learning Without Copying},
author={Kerem Sahin and Sheridan Feucht and Adam Belfki and Jannik Brinkmann and Aaron Mueller and David Bau and Chris Wendler},
year={2025},
eprint={2511.05743},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.05743},
}